
How Did the 2024 Postrider Election Model Hold Up?
We know it’s been a while, but don’t say we didn’t warn you! Our presidential model flirted between Lean Trump and Toss-Up through the last couple weeks of the campaign. And our Senate model remained pretty consistent – Republicans were almost guaranteed to retake the Senate. Sure enough, here we are.
Though our overall approach remained the same as it has in recent years, we did a lot of things differently, stepping up the methodological and technical rigor of our model while building out a much more comprehensive tool that allowed users to use our model and our data to examine the results by plugging in their own assumptions. In the last six weeks of the campaign, we were able to implement probabilistic determination in the model as well, giving a clearer picture of the percent chance each candidate had of winning.
There will be a lot to say about why this election turned out the way it did, what happens now, and what happens in 2026 or 2028, but it’s hard to even start on that without looking at what went right (and what went wrong) with our model in a comparative and predictive sense.
The Big Picture
First off, a technical point – this year was our fourth cycle writing about/rating/modeling Senate races and our second cycle doing the same for a presidential election. Though we now do these through a comprehensive model which actually models the presidential and Senate elections together in the singular Postrider Election Model, it’s easier to write and talk about them by just rhetorically bifurcating it into the “presidential model” or the “Senate model.”
As of the very last update, made the night before Election Day, our model ran with a generic ballot value of D+0.7. The generic ballot helps align the entire model on a central point, so this is important to note. It gave Harris approximately 275 electoral votes, rated the entire race a Toss-Up (57% chance Harris), and gave Trump the edge in every swing state except Michigan. Over on the Senate side, it gave Republicans approximately 52 seats and rated the entire race for control Likely Republican (97% chance of Republicans winning the chamber, right on the cusp of Safe Republican).
For some comparison:
- FiveThirtyEight gave Harris a 50% chance of winning, averaging 270 electoral votes – they take the cake on a national level (though we did quite a bit better state-to-state, more on that below).
- They also gave Republicans a 92% chance of winning the Senate and 52 seats.
- The Economist gave Harris a 56% chance of winning, averaging 276 electoral votes – we did slightly better there, giving her only 275.
- They also gave Republicans only a 71% chance of winning the Senate and 51 seats.
- Split Ticket gave Harris a 53% chance of winning, averaging 270 electoral votes.
- They also gave Republicans only a 73% chance of winning the Senate, and 52 seats.
This puts our presidential model on par (slightly worse at the national level, slightly better at the state-by-state level) and makes our Senate model a clear overperformer – fair enough, as we’ve been doing it more frequently!
By and large, our model did significantly better in terms of the individual state outcomes – if you forced each state to go the direction it tilted, our model would only have missed one presidential race and one Senate race (Michigan and Pennsylvania, respectively).
And, from a data standpoint, our final partisan lean (before adjusting for the estimated national generic ballot) was incredibly accurate on a state-by-state basis. Someone who plugged in R+1.8 (the actual national result) to the data we provided in our model would have gotten the correct winner in every single presidential race.
Read on to get into the nitty gritty.
Presidential Model
Of 56 races (including DC and Maine and Nebraska’s congressional districts, which each allocate a single electoral vote independent of their state), our model “called” the winner correctly (going strictly by who was favored given the projected margin/percentage win odds) in 55 of them. Our only miss – Michigan – was just barely a “Lean Harris” state (60% chance), and ended up going for Trump. Missing the ultimate direction of just one is notably better than any of the aforementioned comparative models, all of whom missed three to four states (we don’t begrudge them – even in those states, they were largely also given toss-up ratings and barely favored Harris, so sometimes that’s just how it cuts!).
But our slightly more rigorous approach this cycle allows for some further reflection: how much were we off on average at the state level, once we look only at partisan lean (our final rating as to how much more Democratic or Republican a state would be, assuming a national popular vote that was exactly tied)? There are a couple notes to make upfront here: first of all, this is looking a step below the final model, in that this looks at the state-level components agnostic to the national popular vote; second – and I’ll make more note of this in a minute – we should probably distinguish between competitive and uncompetitive states while looking at this. Put otherways, this is an exercise in looking at how our expert assessment nudged states from their starting point, then comparing to the actual results, and trying to see if we did a good job or were biased in our application.
The good news is, we really weren’t! On average, we overestimated how Republican states might be by about 0.5 points. This is really good compared to the 3-5 point polling errors that presidential cycles typically have. But we’ll admit to something agnostic to our approach helping us out here: most of the states with the biggest misses were simply estimated to be more Republican than they were, and most of them were not swing states that we put a lot of time into researching or adjusting. That brings us to that second caveat: given the scope of our endeavor this year, we didn’t do a lot of work on states that were pretty clearly in the realm of “Safe” for one party or another, generally just leaving them with the default partisan lean, their shift, and some national factors because it didn’t matter. For example, the “state” we were the most “off” in was the District of Columbia, which our model had as >99% odds of Harris winning (she did), at about D+70 compared to the nation. We didn’t add anything here because it didn’t matter (there was not even a feasible edge probability for DC not to have >99% odds of a Harris victory), and just left it as is without adding any factors or analysis. So, when DC was actually D+85 compared to the nation, we were off by about R+15. This is a pattern that held regardless of the state: we didn’t really adjust safe Republican states like Arkansas, Missouri, and Wyoming; nor safe Democratic states like Hawaii, Massachusetts, and Rhode Island. All had >99% odds, so it was not a priority. We don’t think we should get credit for that (yeah, technically we were almost perfectly on the money in Maryland and Mississippi, which looks really impressive, but I’m telling you we really didn’t do much thinking about those safe states, so please don’t give us special credit for those!), nor criticized for it (no, we didn’t really think DC would shift dramatically rightward this year, we just honestly didn’t adjust it because it didn’t matter. Maybe we’re just lazy… or busy!), so it seems fair to look at our record once you pull these noncompetitive states out.
If we pull out every race that, in our final model, gave the other candidate at least greater than a 2% chance of winning, we’re left with 21 states/districts. In these, we were off on average by about D+0.5, very narrowly overrating how Democratic the more competitive states would be (New Jersey, Florida, and Texas, most notably).
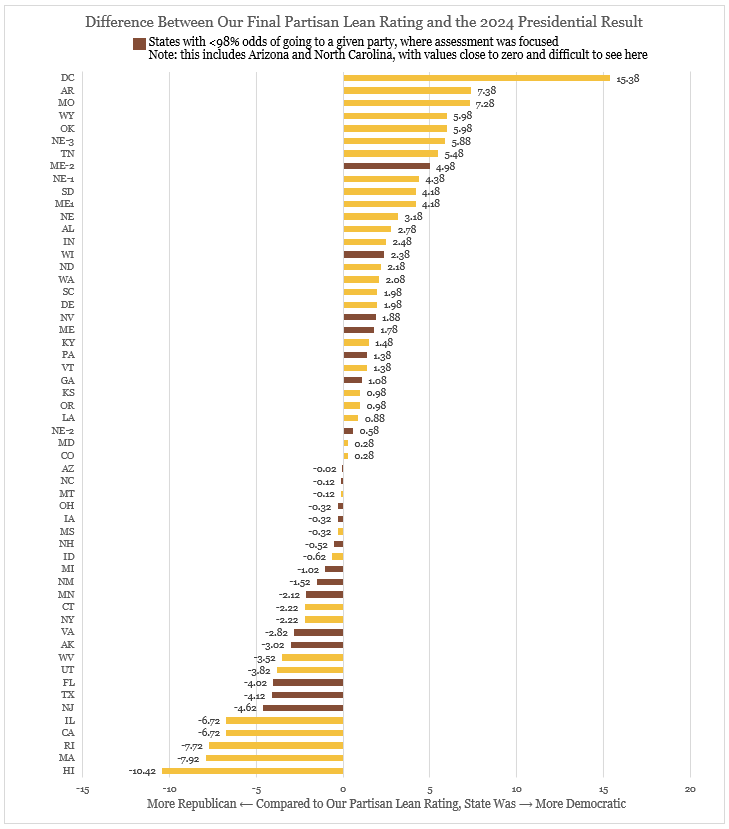
If you took the absolute value of our error in these competitive states, on average we were off by about 1.8 points. Still, this is an enviable margin of error, especially in the core swing states: we were essentially right on the money for partisan lean in states like Arizona, North Carolina, and Nebraska’s Second Congressional District; and far closer than the average polling error in states like Georgia, Nevada, Wisconsin, Pennsylvania, and Michigan.
All of this is to say that, if you plugged R+1.8 – about what Trump won the national popular vote by – into our model, you get very close to the actual results. Every state is correctly called, and all of the swing states are within 0.3 to 2.7 points from their actual result. This is something we can be really proud of, as it shows that our underlying research, data, and approach paid massive dividends.
Once you layer on the final estimated national generic ballot (D+0.7, per FiveThirtyEight), things are a bit more off. Michigan is the only state that “flips” to being outright incorrect there – still fewer misses than the comparable models – and the final Electoral College total is certainly off, but by and large the model pretty adequately addressed the probabilistic issues here and still put us right about on target for the roughly three point polling miss we received between the generic ballot and the actual results.
Where our model, like most, fell the most flat, was in terms of estimating the final Electoral College total. As we wrote back when we unveiled the probability updates in version 1.1 of the model, some of this is the nature of a close election: ultimately the model has to assign electoral votes somewhere, and if several big states are too close to call or merely leaning one way, it’s going to be conservative about that and spread them around. That’s what happened here: whether you take the final D+0.7 generic ballot version of our model, or plug in the actual R+1.8 result, you get a number that’s closer than what the actual result is. As you can see, most of the serious models this cycle suffered from this phenomenon:
| Actual Results | Harris: 226 Electoral Votes | Trump: 312 Electoral Votes |
| Model | Est. Harris Electoral Votes | Est. Trump Electoral Votes |
| Postrider (at final D+0.7) | 275 | 263 |
| Postrider (at actual R+1.8) | 252 | 286 |
| FiveThirtyEight | 270 | 268 |
| The Economist | 276 | 262 |
| Split Ticket | 270 | 268 |
Nate Silver’s model (which is largely paywalled) does get some credit for giving its plurality prediction to the actual results (in that it was the most common across all simulations, appearing about 20% of the time in his model), but this isn’t quite a direct comparison given the distinction between a final estimation and a plurality estimation. Still, it suggests some areas for us to grow which I’ll touch on more in a follow up piece.
By and large, we can rest pretty happy with our work this cycle on the presidential level. Our reporting told some great stories about why states shifted (see Nevada, Arizona, Colorado, New Jersey, North Carolina), and our model proved incredibly stable and with some terrific data accuracy, despite a nailbiter race. Not bad for a scrappy site like ours who built an entire visual infrastructure for the model to boot!
Senate Model
Now let’s turn to the Senate, our bread and butter of ratings and forecasts. Of 34 races (including the Nebraska special election), our model “called” the winner correctly (going strictly by who was favored given the projected margin/percentage win odds) in 33 of them. Our only miss here, Pennsylvania, was a genuine surprise. Even if we put in the actual national generic ballot, we still had the Democrat clearly favored in the Keystone State, as did other models. In fact, this is a less interesting comparison, as this was the only miss that FiveThirtyEight or Split Ticket had too, The Economist also missed the Ohio Senate election.
Nonetheless, we can still probe a bit further. On average (and again, controlling for the generic ballot and national popular vote result) we estimated Senate races to be only D+0.23 more points than they actually were. Adjusting for just the competitive races (see above for why this might be prudent), this falls a bit more to D+0.15.
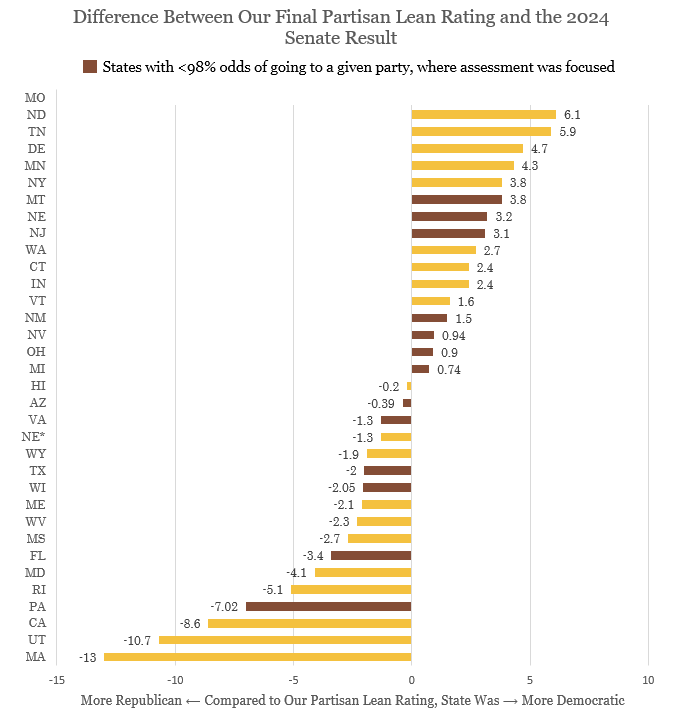
If you took the absolute value of our error in the competitive states, on average we were off by about 2.3 points. A bit worse than our presidential error, but still far better than the average Senate polling error (around 5.4 points) or even the average presidential polling error (around 4.3 points). Though Pennsylvania’s Senate race is a notable outlier (we were about seven points off), we did pretty well in some of the key swing states like Ohio, Nevada, Michigan, and Arizona.
Where our Senate model really stood out is its aggressiveness regarding Republican odds, as it pretty consistently and clearly showed Republicans had about a 97% or 98% chance of taking the chamber. This was always pretty clear to us: Republicans were all-but-guaranteed 50 seats already with a pickup in West Virginia and were clearly favored in Montana, whereas Democrats had to play defense across the map with limited pickup opportunities (Florida or Texas). Our model also pretty consistently projected Republicans landing with 52 or 53 seats (they ended up with 53):
| Actual Results | 53 GOP Seats | |
| Model | Odds of GOP Control | Est. Republican Seats |
| Postrider (at final D+0.7) | 97% | 52 |
| FiveThirtyEight | 92% | 52 |
| The Economist | 71% | 51 |
| Split Ticket | 73% | 52 |
With only one big miss, but with a broadly accurate national assessment, we’re in the wheelhouse for what we’d consider to be a successful 2024 modeling the Senate race. But this year also pointed to some places where we may be able to improve: more consistently applying an incumbency advantage to remove some degree of subjectivity may help smooth out the state-by-state results, and correlating certain factors across states so that they move in tandem, for example.
Our Coverage
We’re very proud of our modeling, to be sure, but we’re also incredibly proud of how we’ve covered this cycle in general. All in, we spent hundreds of hours thinking, talking, and writing about the 2024 election, spread across about a dozen podcast episodes, 60 articles, and our major modeling projects.
It turns out that the things we’ve written about for years – the Rust Belt’s increasing difficulty for Democrats, the impact of the running mates, the importance of addressing economic concerns, fraying Democratic coalitions in states like New Jersey, and Nevada’s redward shift – mattered this year! This is a testament to the importance of looking at the states, looking at their stories, and drawing a narrative. Politics is never just about polls and data, it’s about people and their reactions to events, and our election forecasts have always benefited from this bottom-up, narrative approach. That stories and articles from years ago helped inform really good ratings in states like Arizona, Nevada, Ohio, and Arizona this year speaks to the importance of journalism and coverage at every level of the process, not just in an election year.
This year was also a significant lift in terms of a new development and approach: we took our narrative approach to ratings and applied quantitative data, visualization, interactive features, and more on top of it. This required turning a lot of qualitative information into quantitative estimations, with the hope it’d ostensibly balance out in the end. By and large, it did, but we’re still cautious about reading too much from one year. Reflection, iteration, and improvement are the hallmarks of any useful model, and ours is no exception. We’ll continue to take our successes with a grain of salt and think critically about things we missed.
A final note on our model before we get into some potential areas for improvement: something that sets us apart from other models is our open invitation for users and readers to disagree and tinker with our research and assumptions. Though we’re still a small outlet, and our dreams of the political world (or at least Election Twitter) using our model to create their own predictions and sharing them have yet to manifest, we stand by this option as a reflection of one of our core values. Even if our own research and analysis is great, our assessments are spot on, and our model presents them effectively and with a high degree of accuracy, we may very well be wrong the next cycle. No one is above being wrong, and we have blind spots like everyone else. The idea that we can put some useful information into what we hope is a relatively engaging and easy-to-use tool such that someone could have – with just a few tweaks – run a final version of our model that was 100% accurate is very cool!
I dream of the day where I’m scrolling through Twitter and see that someone has shared a map built using our model that accomplishes this. We hope as our work continues and more people hear about it, that more people join along in this process. Taking our model and beating us may sound like a call for competition, but it’s really a call for engagement and insight. Everyone is prone to error, so why not be upfront about that and invite suggestions and alternatives? Frankly, not only does that sound more interesting, but it sounds more fun.
What’s Next and How We Improve
2025 is an off year for elections, so we’ll be sitting back and taking some time to dig into what else went right or wrong with our efforts in 2024. As this article hints, there are some things we’re looking at that could tangibly improve the Postrider Election Model for 2026, such as correlation, better standardization of qualitative factors, adjusting the elasticity as to how states respond to changes in the national environment.
We have a strong baseline and some cool tech that sets our model apart in terms of interactivity. We’ll want to keep those as a part of our approach going forward, even as we iterate to smooth out the model’s weak spots. To reiterate where I closed off on our coverage: whatever the Postrider Election Model 1.2 brings, we intend for readers to derive value both from using it and – ultimately – building a spot-on forecast from it, even if it means beating us out!